Python
20210926_机器学习预测转录因子结合位点
211

(1)转录因子是一类参与基因表达调控的蛋白质,主要作用是在DNA上结合到特定的序列位置,促进或阻止RNA聚合酶与DNA结合,从而影响基因的转录和表达。转录因子在调控基因表达过程中扮演着非常重要的角色,可以通过启动子区域、增强子区域等DNA序列元素来调控基因的转录,进而影响生物体的生长、发育、代谢、免疫等各个方面。
(2)机器学习预测转录因子结合位点的原理是通过建立一个数学模型来学习已知的转录因子结合位点和非结合位点之间的特征关系,并使用这个模型来预测新的转录因子结合位点。
(3)在这个过程中,机器学习算法会首先从已知的数据集中学习转录因子结合位点和非结合位点的特征,例如DNA序列中的碱基组成和碱基对的数量等。然后,它会使用这些学习到的特征关系来预测新的位点是否是转录因子的结合位点。
(4)要使用机器学习模型来预测转录因子结合位点,你需要收集一些已知的转录因子结合位点和非结合位点的数据,然后使用这些数据来训练机器学习模型。在这里,我将提供一种使用随机森林算法来预测转录因子结合位点的方法,并提供一个简单的数据示例。
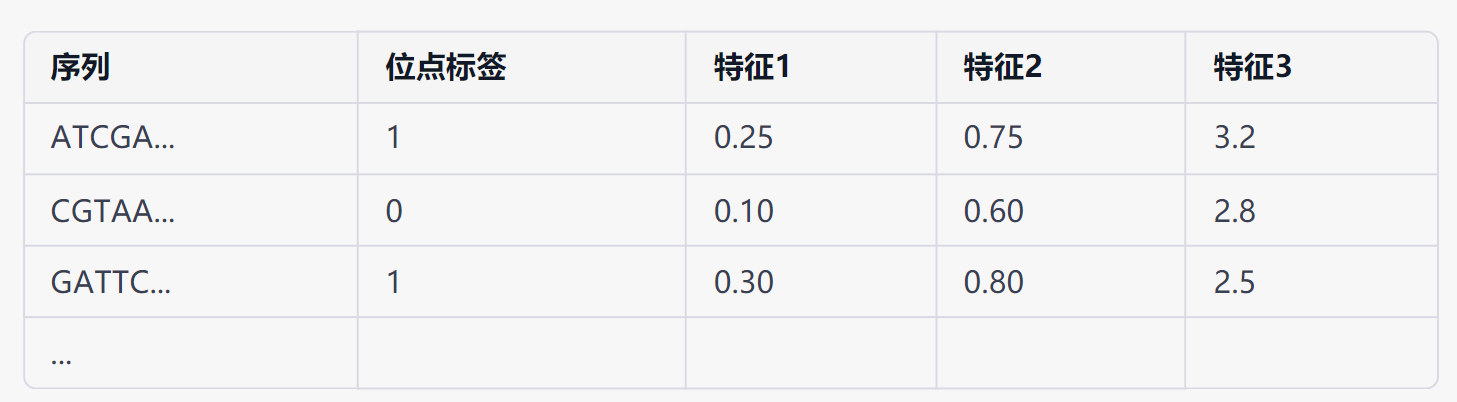
(5)数据准备
我们需要一个包含转录因子结合位点和非结合位点的数据集。数据集可以是一个包含以下列的表格:
- 序列:DNA序列,例如ATCGAGCT...
- 位点标签:一个二元标签,表示这个位点是转录因子的结合位点(1)还是非结合位点(0)
- 其他特征:任何你认为可能对转录因子结合的特征。例如,核苷酸组成,碱基对的数量等。这些特征应该是数字形式。
下面是一个简单的数据示例(dataset.csv):
(6)训练模型
接下来,我们需要使用机器学习算法来训练模型。在这里,将使用Python中的scikit-learn库来实现随机森林算法。
加载数据集
import pandas as pd
df = pd.read_csv("dataset.csv")
数据预处理
X = df.iloc[:, 2:] # 获取除位点标签外的特征列
y = df.iloc[:, 1] # 获取位点标签列
划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
训练随机森林模型
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier(n_estimators=100, random_state=0)
rfc.fit(X_train, y_train)
预测结果
y_pred = rfc.predict(X_test)
评估模型性能
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))
================================================
除了预测转录因子结合位点,机器学习在生物信息学中有许多其他应用:
- 基因表达分析:机器学习模型可以从基因表达数据中学习模式,预测基因表达量与某些生物学特征之间的关系,例如,对基因表达数据进行分类、聚类、预测基因功能等。
- 蛋白质结构预测:机器学习模型可以预测蛋白质的二级结构、三级结构或四级结构等,并可以对其进行分类、聚类、翻译或进行基于结构的药物筛选。
- 生物序列分析:机器学习模型可以预测蛋白质和核酸序列的结构、功能和互作关系,并可以对DNA、RNA和蛋白质序列进行分类、聚类、注释等。
- 基因组学:机器学习模型可以从基因组学数据中预测基因与疾病之间的关系、进行基因组学分类和聚类,预测药物的作用目标和副作用等。
- 总之,机器学习在生物信息学中的应用非常广泛,可以帮助我们更好地理解生物学和疾病机制,加速新药研发,提高医学诊断和治疗的效率。
标签:
bioinfo


北京 天气
晴
1℃
最新文章
推荐阅读
网站浏览
