心情随笔
20240327_基于Python的自动化期刊选择与投稿策略优化方法
479

利用Python编程,我们可以通过自动化的方式分析过去几年中不同期刊发表的相关主题文章数量。通过数据驱动的方法,研究者可以客观地评估各个期刊对其研究领域的兴趣和开放度,从而做出更明智的投稿决策。这种方法不仅节省了手动搜索和比对的时间,而且提供了一种更为客观的评估方式,确保研究人员可以根据历史数据明确看到哪些期刊更倾向于接受与其研究主题相关的论文。通过本文,我们将详细介绍如何收集和处理期刊发表数据,最终帮助研究人员识别出最适合他们工作的期刊。这不仅增强了研究的针对性投稿策略,也提升了论文被接受的可能性。
第一步:
从NCBI下载circular RNA相关文献的信息,保存为pubmed-circularRN-set.txt文件
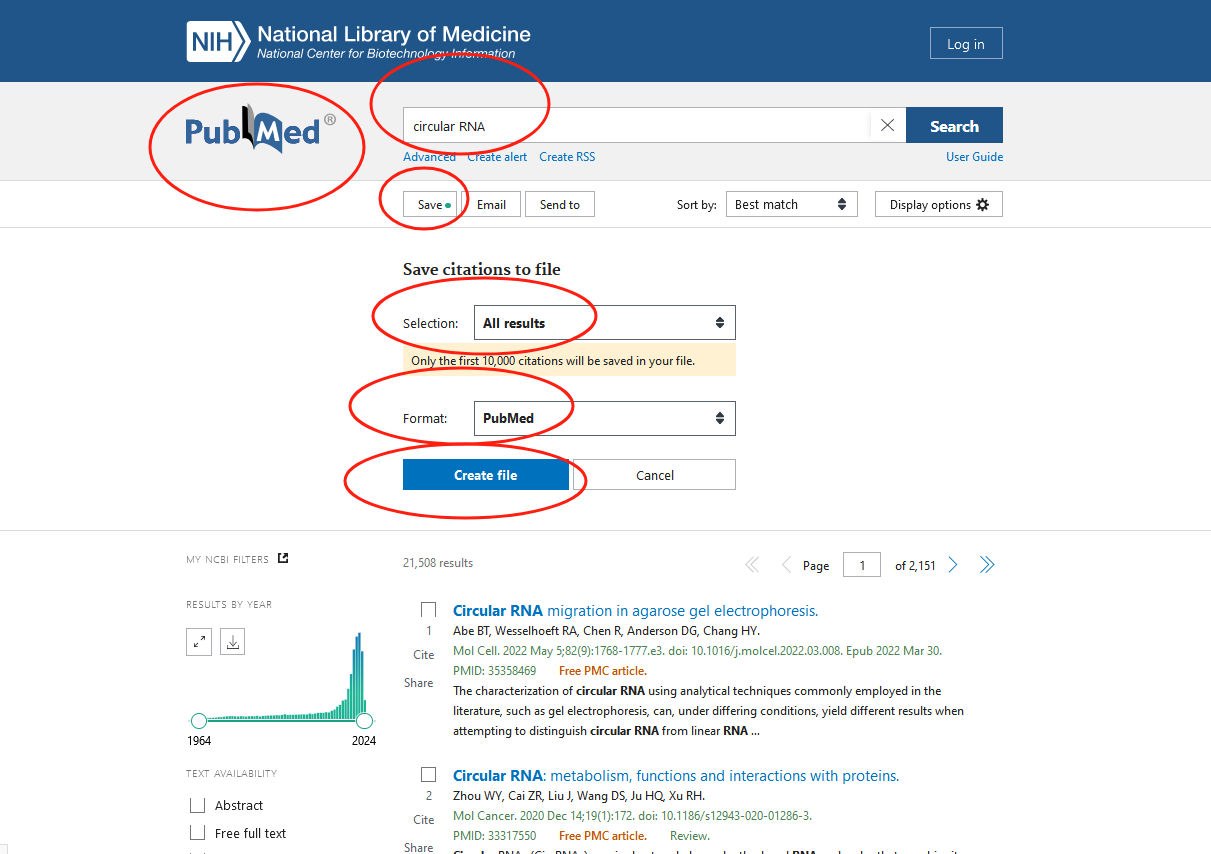
第二步:
https://www.researchgate.net/publication/372770132_Journal_Citation_Reports_JCR_Impact_Factor_2023_IF2023 从这个网站下载sci杂志和其影响因子pdf文件,保存为JournalCitationReportsImpactFactor2023.pdf
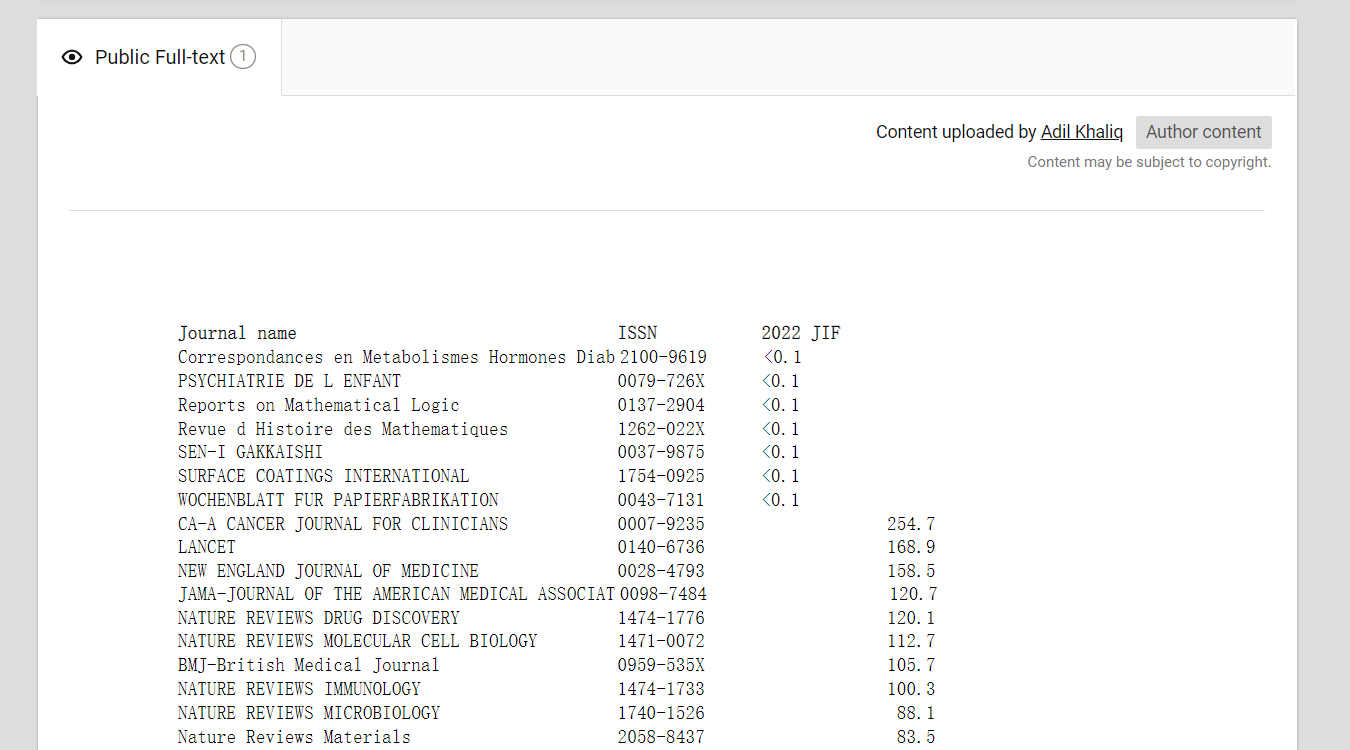
第三步:
执行下述代码
(base) dell@dell-server:~/20240327$ ls -lhtr
总用量 48M
-rw-rw-r-- 1 dell dell 2.9M 3月 27 01:02 JournalCitationReportsImpactFactor2023.pdf
-rw-rw-r-- 1 dell dell 45M 3月 27 01:03 pubmed-circularRN-set.txt
-rw-rw-r-- 1 dell dell 3.4K 3月 27 01:05 journal_select.py
(base) dell@dell-server:~/20240327$ python journal_select.py JournalCitationReportsImpactFactor2023.pdf pubmed-circularRN-set.txt
(base) dell@dell-server:~/20240327$ ls -lhtr
总用量 48M
-rw-rw-r-- 1 dell dell 2.9M 3月 27 01:02 JournalCitationReportsImpactFactor2023.pdf
-rw-rw-r-- 1 dell dell 45M 3月 27 01:03 pubmed-circularRN-set.txt
-rw-rw-r-- 1 dell dell 3.4K 3月 27 01:05 journal_select.py
drwxrwxr-x 2 dell dell 4.0K 3月 27 01:06 pubmed-circularRN-set.txt_output_result
(base) dell@dell-server:~/20240327$ ls -lhtr pubmed-circularRN-set.txt_output_result/
总用量 92M
-rw-rw-r-- 1 dell dell 2.9M 3月 27 01:05 JournalCitationReportsImpactFactor2023.pdf
-rw-rw-r-- 1 dell dell 44M 3月 27 01:06 pubmed-circularRN-set.txt
-rw-rw-r-- 1 dell dell 24K 3月 27 01:06 tmp2.txt
-rw-rw-r-- 1 dell dell 44M 3月 27 01:06 no_blank.txt
-rw-rw-r-- 1 dell dell 34K 3月 27 01:06 tmp3.txt
-rw-rw-r-- 1 dell dell 403K 3月 27 01:06 out2.txt
-rw-rw-r-- 1 dell dell 41K 3月 27 01:06 tmp_final_result.csv
-rw-rw-r-- 1 dell dell 48K 3月 27 01:06 pubmed-circularRN-set.txt_final_result.xlsx
-rw-rw-r-- 1 dell dell 417K 3月 27 01:06 out.txt
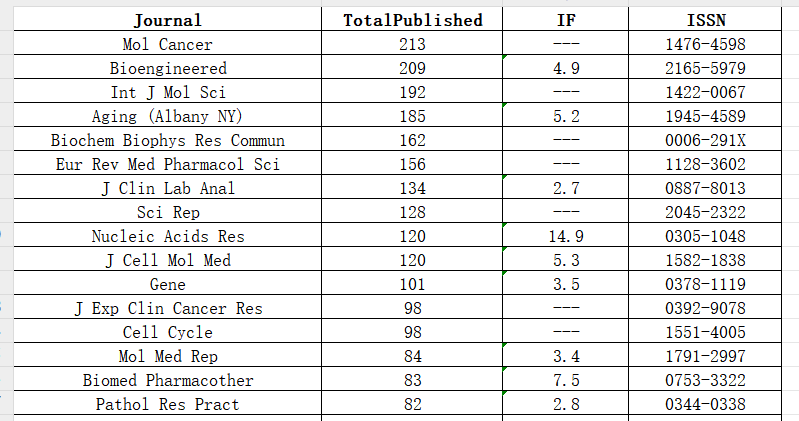
最终结果如图所示:
根据这些杂志往年发表的相关文章数量,以及影响因子和审稿周期,选择合适的杂志作为投稿目标。
journal_select.py 脚本代码:
(base) dell@dell-server:~/20240327$ cat journal_select.py
import pdfplumber as pb
import pandas as pd
import os
import sys
from openpyxl import Workbook
from openpyxl.styles import Alignment
output = sys.argv[2] + "_output_result"
os.system('rm -rf %s && mkdir %s'%(output,output))
os.system('cp %s %s %s'%(sys.argv[1],sys.argv[2],output))
os.chdir('%s'%(output))
jours_if = sys.argv[1]
pubmed_files = sys.argv[2]
file_handle=open('out.txt',mode='w',encoding='utf-8')
# 读取PDF文档
pdf = pb.open( jours_if )
# 绝对路径也可以这么写,下同
# path = 'D:\\GKProject\\需求文档.pdf'
# 获取页数
a= len(pdf.pages)
print("当前页:",a)
print("-----------------------------------------")
i=0
for i in range(0, a):
first_page = pdf.pages[i]
print("本页:",first_page.page_number)
print("-----------------------------------------")
# 导出当前页文本
text = first_page.extract_text()
# print(text)
file_handle.write(text)
os.system('rm -rf ./*tmp*')
pubmed_files = sys.argv[2]
os.system('dos2unix %s'%(pubmed_files))
os.system('grep "doi:" %s | cut -d "." -f 1 | sed \'s/SO - //g\' | sort | uniq -c | sort -r -n | sed \'s/^\\s*//;s/\\s\\+/,/\' | awk -F "," \'{print $2","$1}\' > tmp2.txt'%(pubmed_files))
# issn号码 与 杂志名称对应的字典
issn_dic1=[]
issn_dic2={}
os.system('grep -v "^$" %s > no_blank.txt'%(pubmed_files))
for eles in open("no_blank.txt").read().strip().split("PMID-")[1:] :
ele = eles.strip().split("\n")
for el in ele :
if "(Linking)" in el :
issn = el.strip().split("IS - ")[1].strip().split("(Linking)")[0].strip()
if "SO - " in el :
journal = el.strip().split("SO - ")[1].strip().split(".")[0]
if issn not in issn_dic1 :
issn_dic2[issn] = journal
issn_dic1.append(issn)
#print(issn_dic2)
for eles in issn_dic2:
with open("tmp3.txt","a+") as f :
f.write( eles + "\t" + issn_dic2[eles] + "\n")
# issn号码 与 杂志影响因子的字典
ifscore={}
os.system('grep -v "N/A" out.txt > out2.txt')
for eles in open("out2.txt").read().strip().split("\n"):
ele = eles.strip().split(" ")
#print( ele[-2] + "\t" +ele[-1])
ifscore[ele[-2].strip()] = ele[-1].strip()
os.system('rm -rf tmp_final_result.txt')
for eles in open("tmp2.txt").read().strip().split("\n") :
ele = eles.strip().split(",")
journal = ele[0]
total_num = ele[1]
for name in issn_dic2 :
if issn_dic2[name] == journal :
if name in ifscore :
score = ifscore[name]
else :
score = "---"
with open("tmp_final_result.csv","a+") as f :
f.write( journal + "," + total_num + "," + score + "," + name + "\n")
os.system('sed -i \'1i Journal,TotalPublished,IF,ISSN\' tmp_final_result.csv ')
df = pd.read_csv('tmp_final_result.csv')
final_result = sys.argv[2] + "_final_result.xlsx"
#df.to_excel('%s'%(final_result), index=False)
# 创建一个pandas Excel writer,使用openpyxl作为引擎
writer = pd.ExcelWriter('%s'%(final_result), engine='openpyxl')
# 写入DataFrame数据到writer
df.to_excel(writer, index=False, sheet_name='Sheet1')
# 获取openpyxl的workbook和worksheet对象
workbook = writer.book
worksheet = writer.sheets['Sheet1']
# 对worksheet中的所有单元格设置居中对齐
for col in worksheet.columns:
for cell in col:
cell.alignment = Alignment(horizontal='center')
# 保存文件
writer.save()
标签:
dairly


北京 天气
晴
-7℃
最新文章
推荐阅读
网站浏览
