Python
天池精准医疗大赛—人工智能辅助糖尿病遗传风险预测
247

研究背景:
中国是世界上糖尿病患者最多的国家,病人达到1.1亿,每年有130万人死于糖尿病及其相关疾病。每年用于糖尿病的医疗费用占中国公共医疗卫生支出的比例超过13%,超过3000亿元。本次大赛旨在通过糖尿病人的临床数据和体检指标来预测人群的糖尿病程度,以血糖浓度为指标。参赛选手需要设计高精度,高效,且解释性强的算法来挑战糖尿病精准预测这一科学难题。
竞赛数据:
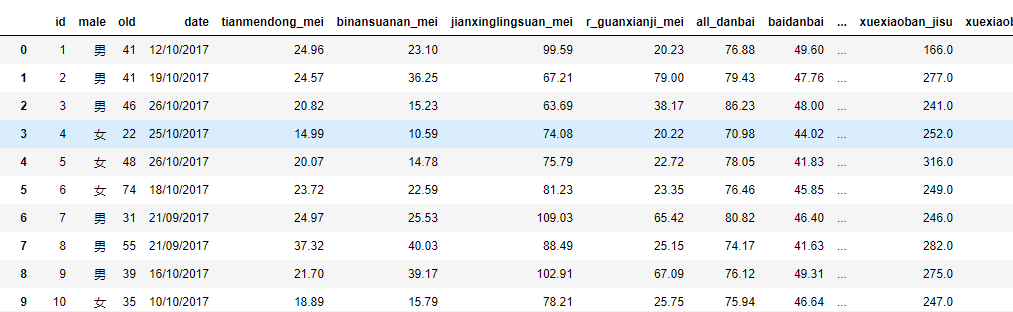
大赛初赛数据共包含两个文件,训练文件d_train.csv和测试文件d_test.csv,每个文件第一行是字段名,之后每一行代表一个个体。文件共包含42个字段,包含数值型、字符型、日期型等众多数据类型,部分字段内容在部分人群中有缺失,其中第一列为个体ID号。训练文件的最后一列为标签列,即需要预测的目标血糖值。
评估指标:
初赛期间,参赛选手需要提交对每个人的糖尿病血糖预测结果,以小数形式表示,保留小数点后三位。该结果将与个体实际检测到的血糖结果进行对比,以均方误差为评价指标,结果越小越好,均方误差计算公式如下:
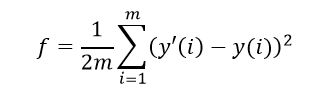
其中m为总人数,y'i 为选手预测的第i个人的血糖值,yi 为第i个人的实际血糖检测值。
优秀参赛作品代码分享:
- 最初想法:使用最近邻的插补方法,即找一条与空缺值相近的且完整的记录对空缺数据的进行插补,将插补后的数据和原始的未插补的数据都带入算法模型中进行验证,发现插补后的数据误差较大,果断放弃。最终仍然使用的是原始的带空缺值的数据用于训练模型。
- 在公布a榜测试集答案后,把a榜的数据作为训练集,把训练集拼接起来,增加了训练集的样本数量。
- 由于最开始的训练集中存在血糖值异常大的记录,删除训练集中血糖为38的那一行。由于与乙肝的缺失值太多,且相关性不高,因此删除了乙肝等5个特征属性,以及删除了‘id’、‘性别’、‘体检日期’特征属性。
- 在开始部分计算了各个特征与‘血糖’的Persona相关性系数,去相关系数较大的几个特征用于训练模型,发现效果不及用33个特征。因此算法模型采用的33个特征,进行血糖的预测。
- 在不断尝试过catboost,LightGBM ,神经网络等基本的算法模型和调参后,发现使用xgboost效果的最好,在无数次不断调参后,达到最优的效果。
import pandas as pd
import xgboost as xgb
from sklearn.metrics import mean_squared_error
# 将两部分的训练集train1,train2共同组合成总得训练集train
train1=pd.read_csv(r"data/d_train_20180102.csv",encoding='gbk')
# 合并训练集
train2_1=pd.read_csv(r"data/d_test_A_20180102.csv",encoding='gbk')
train2_2=pd.read_csv(r"data/d_answer_a_20180128.csv",encoding="gbk",header=None)
train2_2.rename(columns={0:'血糖'},inplace=True) #取名“血糖”
train2=pd.concat([train2_1,train2_2],axis=1)
train=pd.concat([train1,train2],axis=0)
# 删除特别大的‘血糖’异常值
columns=len(train.columns)
train.drop(train.index[[i for i in train.index if train.iloc[i,columns-1]>30]],inplace=True)
# 测试集
test=pd.read_csv(r"data/d_test_B_20180128.csv",encoding='gbk')
# validate=pd.read_csv(r"data/d_answer_b_20180130.csv",encoding='utf-8',header=None)
del_feat=['性别','体检日期','乙肝表面抗原', '乙肝表面抗体', '乙肝e抗原', '乙肝e抗体', '乙肝核心抗体']
# 删除特征
feat=[]
for i in train.columns:
if i not in del_feat:
feat.append(i)
train=train[feat]
feat.remove('血糖') #测试集不需要‘血糖’属性
test=test[feat]
y_train = train["血糖"]
x_train = train.drop(['id','血糖'], axis=1)
y_test = test.drop('id', axis=1)
# training xgboost
dtrain = xgb.DMatrix(x_train, label=y_train)
dtest = xgb.DMatrix(y_test)
params = {'booster': 'gbtree',
'objective': 'reg:linear',
'eval_metric': 'rmse',
'max_depth': 6,#通常取值:3-10
'gamma':0.2,#给定了所需的最低loss function的值
'lambda': 100,
'subsample': 1,#用于训练模型的子样本占整个样本集合的比例
'colsample_bytree': 0.6,
'min_child_weight': 12, # 5~10,孩子节点中最小的样本权重和,即调大这个参数能够控制过拟合
'eta': 0.02,#更新过程中用到的收缩步长,取值范围为:[0,1]
'sample_type': 'uniform',
'normalize': 'tree',
'rate_drop': 0.1,
'skip_drop': 0.9,
'seed': 100,
'nthread':-1
}
bst_nb = 700
watchlist = [(dtrain, '训练误差')]
model = xgb.train(params, dtrain, num_boost_round=bst_nb, evals=watchlist) # 训练模型
y_pred = model.predict(dtest)
# print((mean_squared_error(validate,y_pred))/2)
y_predDF=pd.DataFrame({None:y_pred})
y_predDF.to_csv("SMUDMers_test_B_res.csv",header=None,index=False,float_format="%.2f")
其它优秀参赛作品:
https://tianchi.aliyun.com/forum/post/3794
https://www.yuque.com/xunyi-gbcvx/lwka1v/fcqhus
https://tianchi.aliyun.com/forum/post/3794
https://tianchi.aliyun.com/notebook/24474
https://tianchi.aliyun.com/forum/post/4714
https://tianchi.aliyun.com/forum/post/4821
https://tianchi.aliyun.com/forum/post/4687
https://tianchi.aliyun.com/forum/post/4828
https://zhuanlan.zhihu.com/p/85271971
标签:
bioinfo


北京 天气
晴
1℃
最新文章
推荐阅读
网站浏览
